



Enterprise AI infrastructure is shifting from the Ampere generation to Hopper, driven by growing demand for large language models, high-throughput analytics, and production-scale inference. Organizations that once relied on A100 GPUs are now evaluating how to upgrade without disrupting existing server environments.
The NVIDIA 900-21010-0000-000 H100 PCIe provides a practical path forward. With 80GB of high-bandwidth memory, PCIe Gen5 compatibility, and Hopper architecture enhancements, it enables advanced AI acceleration inside standard data center systems.
The central decision is not whether the H100 PCIe delivers strong performance. It does, but whether it is the right fit compared with SXM5-based deployments, previous-generation A100 PCIe GPUs, or alternatives like AMD Instinct MI300X. Deployment speed, infrastructure compatibility, and long-term operational efficiency are often the determining factors.
Delays in AI infrastructure can slow model deployment and increase compute inefficiency. Selecting the right GPU platform early helps avoid costly redesigns later.
Key Takeaways:
- Delivers 80GB HBM2e memory, PCIe Gen5 connectivity, and Hopper architecture for enterprise AI and HPC workloads
- Enables cost-efficient Hopper adoption through refurbished, enterprise-validated deployment in standard PCIe server environments
- Supports FP8 precision and Transformer Engine, accelerating AI training up to 4x and inference up to 30x
- Best suited for inference, mid-scale training, and hybrid workloads; less optimal for large-scale NVLink-based GPU clusters
Overview of NVIDIA H100 PCIe
What Is the NVIDIA 900-21010-0000-000 H100 PCIe
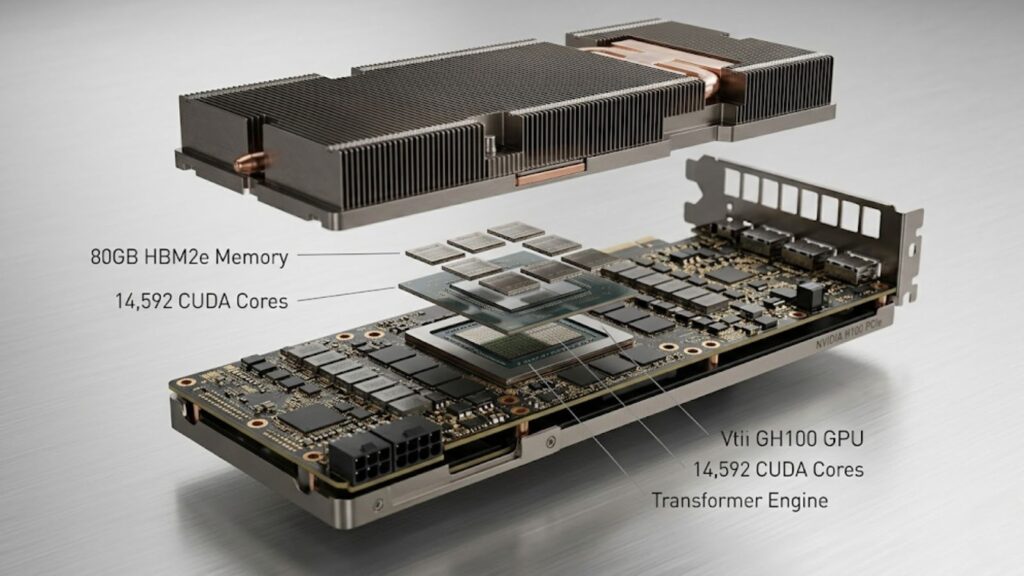
The NVIDIA H100 PCIe is a Hopper-generation GPU designed for enterprise AI, HPC, and data analytics workloads. Unlike the SXM5 variant, it uses a standard PCIe form factor, making it compatible with a wide range of existing servers and workstations.
The 900-21010-0000-000 model delivers enterprise-grade performance while maintaining flexibility in deployment.
Key Specifications Snapshot
| Specification | Details |
| GPU Architecture | Hopper |
| Memory | 80GB HBM2e |
| Memory Bandwidth | ~2 TB/s |
| CUDA Cores | 14,592 |
| Tensor Cores | 456 (4th Gen) |
| Interface | PCIe Gen5 |
| Power (TDP) | 350W–400W |
| Precision Support | FP8, FP16, BF16, TF32, FP64, INT8 |
| Multi-GPU | NVLink Bridge Support |
Refurbished Positioning and Enterprise Relevance
This specific model is refurbished with enterprise-grade assurance, meaning it has been validated for reliability and performance consistency in production environments while providing a cost-conscious path to Hopper adoption. Organizations can access advanced AI capabilities without committing to full new-system procurement cycles.
This approach is particularly relevant when paired with existing enterprise server infrastructure that supports PCIe accelerators.
Target Buyers and Deployment Environments
The H100 PCIe is designed for:
- Enterprises upgrading from A100 PCIe
- AI teams deploying production inference
- Data centers with standard rack-mounted servers
- Organizations managing power-constrained environments
Architecture and Platform Analysis
Hopper Architecture and Transformer Engine
The H100 PCIe is built on the Hopper architecture from NVIDIA, introducing the Transformer Engine. This feature dynamically adjusts precision between FP8 and higher formats, improving efficiency for transformer-based models.
This is particularly relevant for LLMs and generative AI workloads.
Why FP8 Support Matters for Modern AI Workloads
FP8 precision significantly reduces memory usage and compute overhead. This enables:
- Faster training cycles
- Higher throughput inference
- Improved GPU utilization
For organizations scaling AI workloads, faster inference and more efficient training can directly improve time-to-market.
PCIe Form Factor, Gen5 Connectivity, and Standard Server Fit
PCIe Gen5 provides:
- Up to 128 GB/s bandwidth
- Compatibility with mainstream server platforms
- Easier integration into existing data center environments
This aligns with organizations operating within data center infrastructure that prioritize flexibility, allowing Hopper GPUs to be deployed across a wide range of standard server platforms without requiring specialized systems.
NVLink Bridge Support and Its Practical Scaling Limits
The H100 PCIe supports NVLink bridges for multi-GPU scaling within a single node, enabling higher performance for parallel workloads. However:
- It does not match SXM5’s NVLink 4.0 bandwidth
- It is not optimized for massive GPU clusters
This makes it suitable for node-level scaling, rather than hyperscale AI training environments.
Performance Review and Capability Analysis
AI Training Performance vs Previous Generation
Compared to A100, the H100 introduces a major performance leap. NVIDIA reports up to 4x faster training for GPT-3 175B-scale models, driven by architectural improvements and the Transformer Engine.
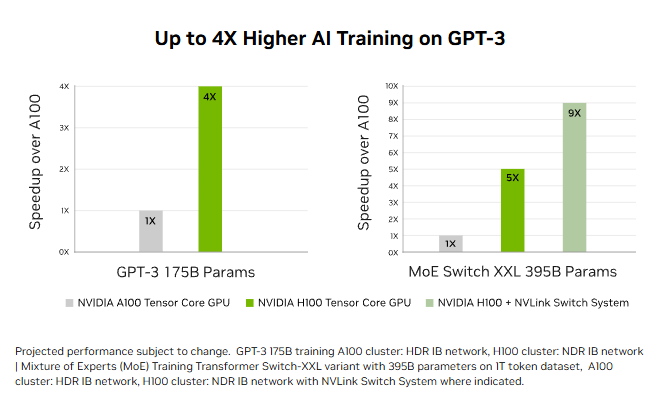
This improvement is most visible in transformer-heavy workloads.
Inference Acceleration for LLM and Production AI Workloads
Inference performance is a key strength. NVIDIA reports up to 30x higher inference performance in certain LLM workloads, making the H100 PCIe highly effective for production deployments.
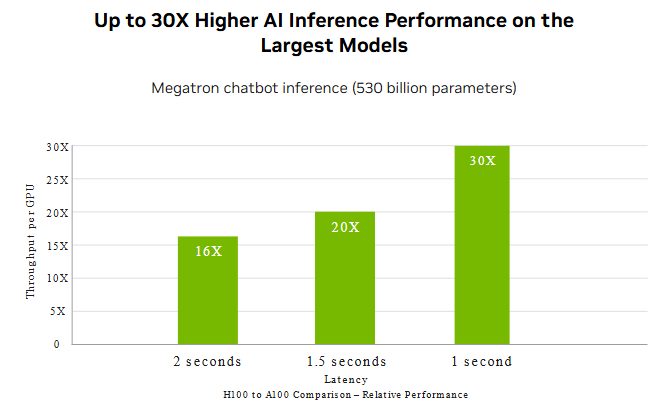
This is particularly valuable in:
- Chatbot services
- Recommendation systems
- Real-time analytics pipelines
HPC and Data Analytics Performance Value
Beyond AI, the H100 PCIe supports:
- Scientific simulations
- Financial modeling
- Data-intensive analytics
Its balance of compute and memory bandwidth allows it to handle complex workloads within a single-node environment.
Where PCIe Performance Differs from SXM5 in Real Deployments
The main differences appear in:
- Memory bandwidth (lower than SXM5)
- Interconnect performance (PCIe vs NVLink)
- Multi-node scalability
For many enterprises, these differences are acceptable in exchange for deployment flexibility.
Memory, Throughput, and Precision Support

80GB HBM Memory and ECC Reliability
The GPU includes 80GB of HBM2e memory with ECC protection, ensuring reliability for enterprise workloads.
This capacity supports:
- Medium-to-large model training
- High-throughput inference
- Data-heavy analytics
Approximate 2 TB/s Memory Bandwidth in Context
At ~2 TB/s, the H100 PCIe offers strong memory throughput, though lower than SXM5’s HBM3-based bandwidth.
This impacts:
- Large model training efficiency
- Data movement-heavy workloads
Supported Precisions
The GPU supports:
- FP8 (AI acceleration)
- FP16 / BF16 (training)
- TF32 (balanced workloads)
- FP64 (HPC)
- INT8 (inference optimization)
This flexibility allows adaptation across diverse workloads.
When Memory Bandwidth Becomes the Limiting Factor
Bandwidth limitations become noticeable when:
- Training extremely large models
- Running multi-GPU distributed workloads
- Processing large datasets with high I/O demands
PCIe vs SXM5: What Actually Changes

Power, Cooling, and Infrastructure Requirements
| Feature | H100 PCIe | H100 SXM5 |
| Power | 350W–400W | Up to 700W |
| Cooling | Air or Liquid | Typically Liquid |
| Deployment | Standard Servers | Specialized Systems |
Lower power requirements make PCIe easier to deploy in existing environments.
HBM2e vs HBM3 and Memory Trade-Offs
- PCIe: HBM2e (~2 TB/s)
- SXM5: HBM3 (~3.35 TB/s)
The difference affects large-scale training workloads.
PCIe Gen5 vs NVLink 4.0 Interconnect
- PCIe: 128 GB/s
- NVLink 4.0: up to 900 GB/s
This is a major factor in multi-GPU scaling performance.
Which Organizations Should Choose PCIe Instead of SXM5
PCIe is better suited for:
- Standard server environments
- Moderate AI workloads
- Cost-conscious deployments
- Faster deployment timelines
Enterprise Deployment Considerations

Server Compatibility and Integration Simplicity
The PCIe form factor allows integration into most modern servers without requiring proprietary systems. This reduces deployment complexity.
This aligns with teams planning GPU deployment strategies within existing infrastructure.
Power Envelope and Thermal Planning
With a 350W–400W TDP:
- Easier to manage in current racks
- Lower cooling requirements
- Reduced infrastructure upgrades
For many organizations, this avoids expensive redesigns of AI cooling systems.
Hybrid Data Center and On-Prem AI Use
The H100 PCIe fits well into:
- Hybrid cloud environments
- On-prem AI deployments
- Edge-adjacent compute nodes
Why Refurbished H100 PCIe Can Be a Strategic Buy
Refurbished models provide:
- Lower acquisition cost
- Faster availability
- Enterprise validation
This makes them attractive for scaling AI infrastructure efficiently, particularly for cost-sensitive deployments that still require Hopper-level performance.
Use Cases and Workload Fit

Production AI Inference in PCIe Servers
The H100 PCIe is highly effective for:
- Real-time inference pipelines
- API-driven AI services
- Scalable application deployment
Fine-Tuning and Mid-Scale AI Training
Suitable for:
- Model fine-tuning
- Mid-sized training workloads
- Development environments
HPC, Simulation, and Data Analytics
Its compute capabilities support:
- Scientific workloads
- Financial simulations
- Engineering models
Mixed Enterprise Workloads in Hybrid Environments
The GPU handles:
- Concurrent AI + analytics workloads
- Cost-efficient deployment of Hopper performance across hybrid data center environments
- Virtualized GPU environments
- Multi-tenant deployments
Competitor Analysis and Comparison
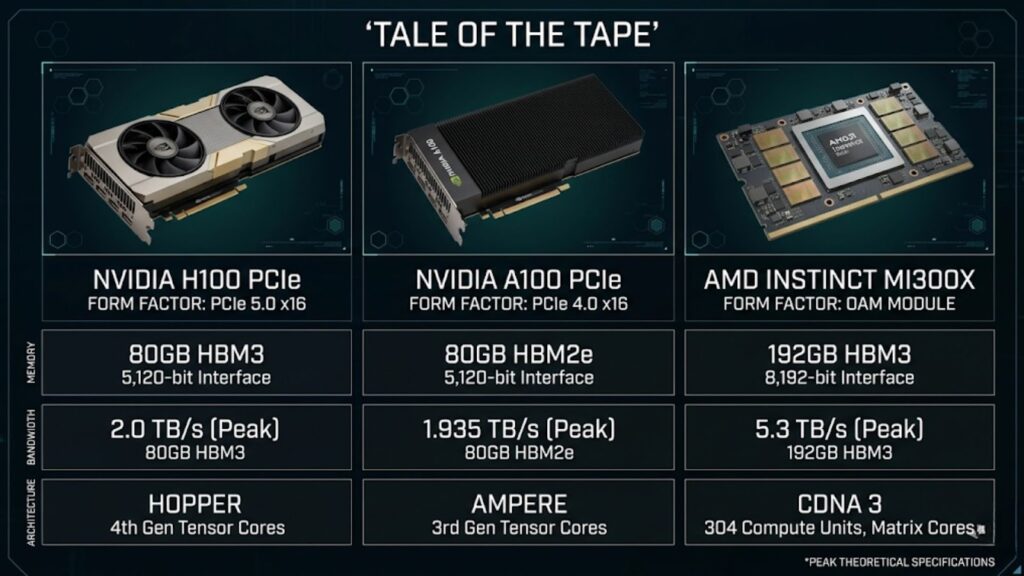
H100 PCIe vs H100 SXM5
- SXM5 offers higher performance and scalability
- PCIe offers flexibility and lower infrastructure requirements
H100 PCIe vs NVIDIA A100 PCIe
- H100 delivers significantly higher performance
- FP8 support improves efficiency
- Better suited for modern AI workloads
H100 PCIe vs AMD Instinct MI300X
| Feature | H100 PCIe | A100 PCIe | MI300X |
| Memory | 80GB | 80GB | 192GB |
| Bandwidth | ~2 TB/s | ~2 TB/s | ~5.3 TB/s |
| Architecture | Hopper | Ampere | CDNA 3 |
| AI Optimization | High | Moderate | High |
The MI300X offers higher memory capacity and bandwidth, making it suitable for memory-heavy workloads.
Which Accelerator Fits Inference, Training, and HPC Best
- Inference: H100 PCIe
- Massive training: SXM5
- Memory-heavy workloads: MI300X
- Legacy environments: A100 PCIe
Pricing, Availability, and ROI Perspective
Why H100 PCIe Remains a Premium Infrastructure Purchase
The H100 PCIe typically ranges from $25,000–$30,000, reflecting its enterprise-grade performance.
Refurbished vs New Procurement Considerations
Refurbished units offer:
- Lower upfront cost
- Faster deployment
- Comparable performance
- A practical way to access Hopper architecture for organizations balancing performance needs with budget constraints
Infrastructure Cost vs Deployment Flexibility
PCIe deployment avoids:
- Specialized server costs
- Advanced cooling systems
- Complex integration
Total Value in Standard-Server Environments
For many organizations, PCIe delivers the best balance of:
- Performance
- Cost
- Deployment simplicity
Advantages and Limitations

Main Strengths
- Strong AI inference performance
- PCIe Gen5 compatibility
- Lower power requirements
- Broad server compatibility
- Cost-effective refurbished options
Main Constraints
- Lower memory bandwidth vs SXM5
- Limited multi-GPU scaling
- High upfront cost
Best-Fit and Poor-Fit Scenarios
Best Fit:
- Production inference
- Mid-scale training
- Standard data centers
Poor Fit:
- Massive distributed training
- Hyperscale GPU clusters
Final Verdict
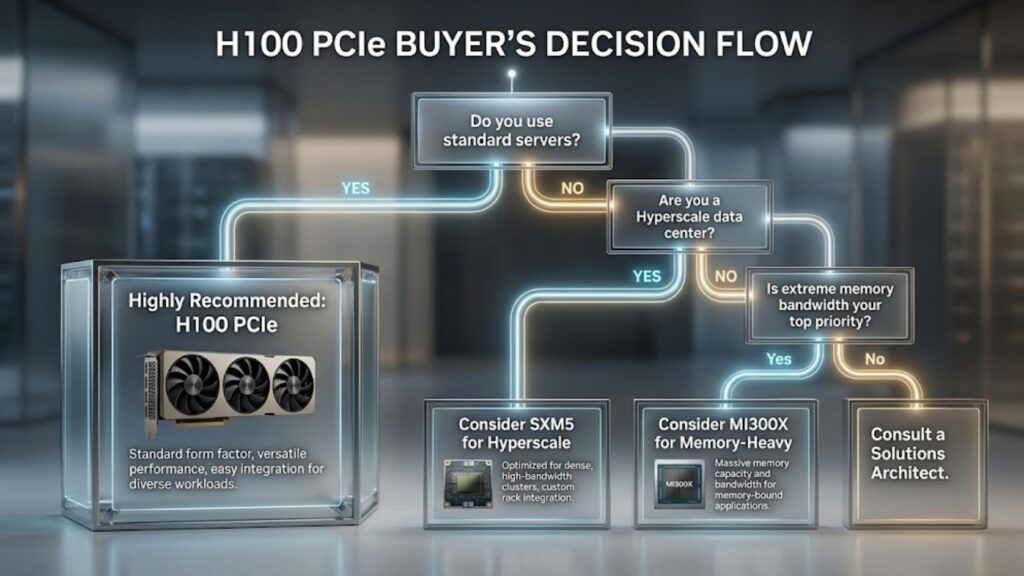
Who Should Buy the H100 PCIe
Organizations that:
- Use standard servers
- Prioritize deployment flexibility
- Focus on inference and moderate training
When H100 SXM5 Is the Better Choice
- Large-scale AI training
- Maximum performance requirements
- NVLink-heavy environments
When A100 PCIe or MI300X May Make More Sense
- A100: budget-constrained upgrades
- MI300X: memory-intensive workloads
Need Help Choosing the Right NVIDIA H100 PCIe Deployment?
Catalyst Data Solutions Inc. can help evaluate whether the NVIDIA H100 PCIe fits your server infrastructure, workload scale, and deployment goals.
For teams comparing H100 PCIe with SXM, A100, or other enterprise accelerators, the right platform choice early can reduce upgrade friction and support faster AI rollout.
FAQs
What is the difference between H100 PCIe and H100 SXM5?
The PCIe version prioritizes compatibility and flexibility, while SXM5 focuses on maximum performance and scalability.
Is H100 PCIe better than A100 PCIe for AI workloads?
Yes, due to Hopper architecture improvements and FP8 support.
Is the H100 PCIe suitable for LLM inference?
Yes, it is optimized for high-throughput inference workloads.
Does H100 PCIe support NVLink?
Yes, but only through bridge configurations with limited scalability.
Is 80GB enough for enterprise AI and HPC workloads?
For most inference and mid-scale training workloads, yes. Larger models may require more memory.
Why would a buyer choose a refurbished H100 PCIe?
To reduce cost while maintaining enterprise-grade performance.
What kind of servers support the H100 PCIe?
Most modern PCIe Gen4/Gen5 servers have sufficient power and cooling.
When is MI300X a better option than H100 PCIe?
When workloads require significantly higher memory capacity and bandwidth.